La mayoría de las herramientas de dictado envían tu voz a un servidor en la nube. El audio se transcribe allí, el texto se almacena allí y una copia permanece en la base de datos del proveedor hasta que la eliminas (y a veces incluso después). Para una nota de voz rápida, esto está bien. Para un correo electrónico de un cliente sobre un asunto confidencial, un mensaje de Slack revisando un trato o la nota de sesión de un terapeuta, es un problema que el proveedor no resolverá por ti.
Esta guía explica a dónde va realmente tu voz cuando dictas, la escalera de privacidad de tres peldaños que determina cuánto control conservas y qué herramientas en 2026 ofrecen qué peldaños. La versión corta: solo una herramienta de dictado te da los tres peldaños de control, y puedes apilarlos para que ninguna solicitud salga nunca de tu máquina.
Conclusiones rápidas
- La mayoría de las herramientas de dictado (Wispr Flow, Willow Voice, Otter, voz de ChatGPT) son solo en la nube. Tu audio sale de tu dispositivo antes de que se transcriba una palabra.
- La escalera de privacidad de tres peldaños: procesamiento de modelo local, trae tu propia clave (BYOK) y deshabilitar la sincronización en la nube. Cada peldaño te devuelve un tipo específico de control.
- Apple Dictation se ejecuta en el dispositivo pero no ofrece personalización ni salida consciente del contexto, y Apple aún recopila telemetría de uso.
- MacWhisper y Superwhisper se ejecutan localmente en Mac pero no te dan BYOK ni modos conscientes del contexto.
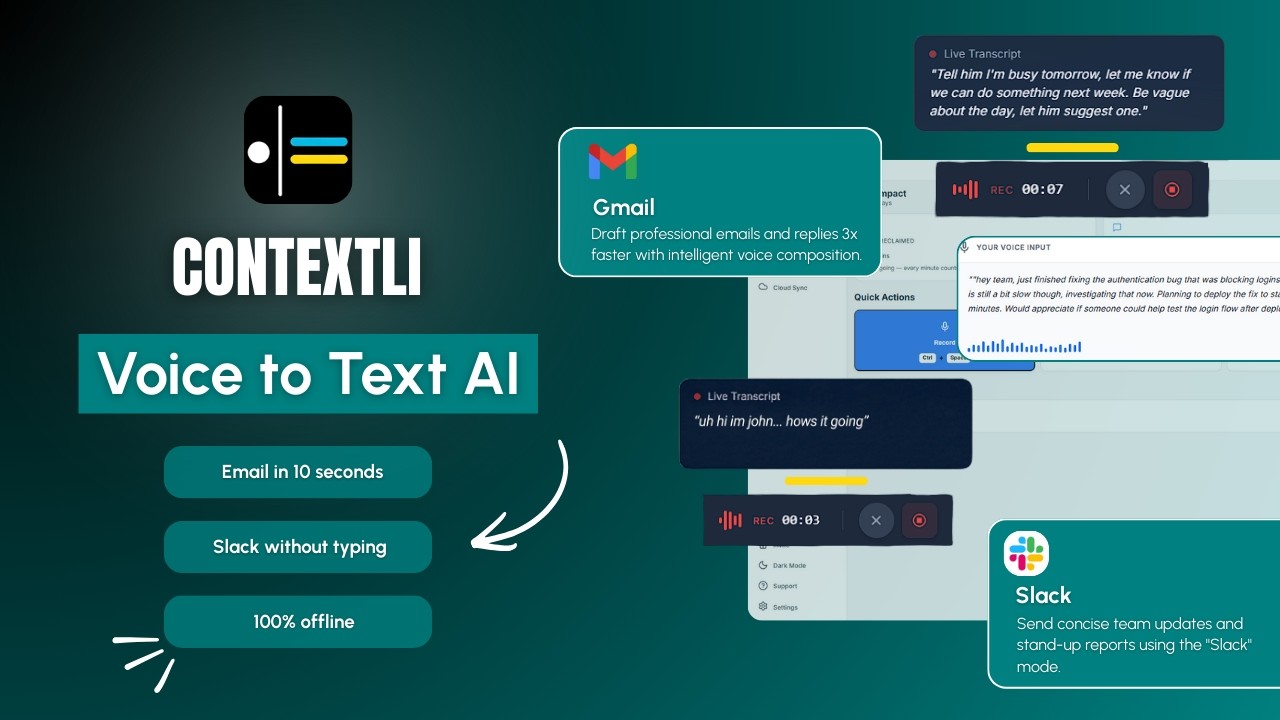
- Contextli es la única herramienta de dictado en 2026 que te permite apilar los tres peldaños: modelo local, BYOK y sin sincronización en la nube. Combínalos y Contextli nunca realiza una solicitud a ningún servidor externo.
A dónde va tu voz cuando dictas
Cuando presionas la tecla de acceso rápido para dictar en una herramienta típica basada en la nube, esto es lo que sucede en los primeros 400 milisegundos. Tu micrófono captura el audio. La aplicación lo codifica. El audio se envía a través de internet al servidor de transcripción del proveedor. Un modelo de voz a texto devuelve el texto. Para las herramientas conscientes del contexto, un segundo modelo reescribe el texto para el canal en el que estás escribiendo. La cadena final regresa a tu máquina. El proveedor registra la solicitud.
La mayoría de los usuarios no notan nada de esto. Lo que sí notan es que presionar la tecla de acceso rápido funciona bien en el tren con Wi-Fi irregular (porque el viaje de ida y vuelta a la nube se reintenta silenciosamente) y que la transcripción aparece en sus notas, quieran o no que se almacene.
Las preguntas sobre privacidad son sencillas, pero los proveedores rara vez las responden en un solo lugar. ¿A dónde va el audio? ¿Quién tiene acceso a las transcripciones? ¿Cuánto tiempo se guarda todo? ¿Se puede desactivar algo de esto? En 2026, la mayoría de las herramientas de dictado populares responden bien a una o dos de estas preguntas y guardan silencio sobre el resto.
La escalera de privacidad de tres peldaños
Hay tres controles independientes que determinan cuán privada es realmente tu dictado. Las herramientas difieren en los controles que ofrecen. La configuración más sólida utiliza los tres.
Peldaño 1: Procesamiento de modelos local
El primer peldaño es si el modelo de voz a texto y el modelo de escritura consciente del contexto se ejecutan en tu propia máquina o en la nube. Cuando los modelos se ejecutan localmente, tu audio nunca sale de tu dispositivo. Internet puede estar desconectado. La aplicación sigue funcionando.
Esto solía ser un problema de hardware. Los modelos de voz locales necesitaban un rack de servidores. Hoy en día, una Mac moderna con Apple Silicon (M1 y posteriores) o una laptop con Windows de los últimos tres años ejecuta transcripciones de clase Whisper localmente a una velocidad superior a la del tiempo real. MacWhisper, por ejemplo, ejecuta el modelo Whisper de OpenAI completamente en el dispositivo y reporta hasta 15 veces la velocidad en tiempo real en Apple Silicon, con una transcripción de 1:12 en chips M4. La compensación es honesta: una laptop de diez años será lenta, y las laptops con batería se agotan más rápido durante las sesiones de dictado largas.
Las grandes herramientas solo en la nube no tienen modo local en ningún nivel de precio. La documentación de Wispr Flow establece que la transcripción siempre se realiza en la nube "para proporcionar la mejor velocidad y precisión". Willow Voice es solo en la nube por diseño. Otter, la voz de ChatGPT, AudioPen y la mayoría de las herramientas de dictado recomendadas en listas son todas solo en la nube.
Peldaño 2: Trae tu propia clave (BYOK)
El segundo peldaño es lo que sucede cuando usas la nube. Por defecto, una herramienta de dictado basada en la nube enruta tu audio a través de sus propios servidores, utiliza sus propios proveedores de transcripción e IA contratados (a menudo OpenAI, Anthropic, Deepgram o AssemblyAI) y devuelve el resultado. El proveedor se interpone en cada solicitud.
BYOK cambia esto. Tú proporcionas tu propia clave API para el proveedor de transcripción y el proveedor de IA. Las solicitudes van directamente desde tu máquina al proveedor que elegiste. El proveedor de dictado nunca ve el audio ni el texto procesado. Tú pagas directamente al proveedor, lo que generalmente cuesta menos por minuto que una suscripción fija si dictas mucho.
En 2026, casi ninguna herramienta de dictado para el consumidor ofrece BYOK verdadero. Wispr Flow no lo hace. Willow Voice no lo hace. El Dictado Nativo de Apple no lo hace (es solo en el dispositivo, sin necesidad de opción BYOK). Las pocas opciones BYOK que existen son principalmente para desarrolladores o autoalojadas.
Peldaño 3: Desactivar la sincronización en la nube
El tercer peldaño es lo que sucede con tus transcripciones después de dictar. La mayoría de las herramientas de dictado basadas en la nube sincronizan tu historial de transcripciones con su base de datos por defecto para que puedas acceder a él desde otro dispositivo. Esta es una característica de conveniencia, no un requisito técnico.
Normalmente puedes desactivarla. Contextli trata la sincronización en la nube como una característica controlada por el usuario: habilitada por defecto para el uso entre dispositivos, pero puedes desactivarla. Cuando está desactivada, las notas transcritas se guardan como archivos locales en tu máquina. Puedes explorarlas en Finder o el Explorador de Archivos. La base de datos de Contextli no almacena nada sobre ti.
Wispr Flow añadió recientemente el "Modo de Privacidad" que describen como retención cero en el servidor. El audio aún sale de tu dispositivo para la transcripción y el reformateo, pero lo eliminan después. Esto no es lo mismo que el Peldaño 3, que se refiere a si los datos van a su base de datos en absoluto. Es un paso significativo, pero sigues confiando en una política de eliminación.

Qué herramientas de dictado ofrecen qué funciones en 2026
Verificado con la documentación del proveedor en mayo de 2026. Los precios y las características cambian. Confirme antes de confiar en esto para el cumplimiento.
| Herramienta |
Modelo local |
BYOK |
Desactivar sincronización en la nube |
Conciencia de pantalla opcional |
Modos personalizables |
| Contextli |
Sí |
Sí |
Sí |
Sí (opcional) |
Sí |
| Wispr Flow |
No |
No |
Solo "Modo de privacidad" |
Capturas de pantalla automáticas |
No |
| Willow Voice |
No |
No |
No |
No |
No |
| MacWhisper |
Sí |
n/a |
Sí (solo local) |
No |
No |
| Superwhisper |
Sí |
n/a |
Sí (solo local) |
No |
No |
| Apple Dictation |
Sí |
n/a |
Sí (telemetría) |
No |
No |
| Otter.ai |
No |
No |
No |
No |
No |
| ChatGPT voice |
No |
No |
No |
No |
No |
Una nota sobre la captura de pantalla de Wispr Flow: su documentación revela que la aplicación captura capturas de pantalla de la ventana activa cada pocos segundos para sugerencias conscientes del contexto, enviadas a servidores en la nube con la grabación de voz. Esto está activado por defecto. La función equivalente de Contextli (conciencia de pantalla) está desactivada por defecto y es explícitamente opcional.
Cómo apilar los tres peldaños con Contextli
La pila más fuerte utiliza los tres peldaños juntos. Así es como funciona en Contextli, paso a paso. La configuración de conciencia de pantalla permanece desactivada (que es la predeterminada) para esta configuración.
Primero, en la configuración de Contextli, cambie la transcripción a un modelo local. La aplicación descarga el modelo de clase Whisper la primera vez, luego mantiene todo en su máquina. Internet puede estar apagado. La velocidad de transcripción es aproximadamente en tiempo real en una computadora portátil moderna, un poco más lenta que Wispr Flow solo en la nube a la velocidad máxima, pero la ventaja es que su audio nunca sale del dispositivo.
En segundo lugar, cambie el modelo de escritura con reconocimiento de contexto a local también, o configure BYOK con su propia clave de proveedor (OpenAI, Anthropic o su elección). Si opta por ser completamente local, el modelo de escritura también se ejecuta en su máquina. Si opta por BYOK, la solicitud va de su máquina al proveedor que eligió, nunca a través de los servidores de Contextli.
En tercer lugar, en el mismo panel de configuración, desactive la sincronización en la nube. Sus notas transcritas ahora solo viven como archivos locales en una carpeta que usted controla. Puede explorarlas, hacer copias de seguridad o eliminarlas usted mismo. La base de datos de Contextli no almacena nada.
Con los tres peldaños apilados, este es el flujo de trabajo: una consultora acaba de terminar una llamada confidencial con un cliente. Abre su cliente de correo electrónico, presiona la tecla de acceso rápido de Contextli y dicta el seguimiento usando el Modo Correo Electrónico. El audio es transcrito por el modelo local en su computadora portátil. El Modo Correo Electrónico (la capa de escritura con reconocimiento de contexto) lo reformatea en un correo electrónico de cliente correctamente estructurado, también localmente. El texto final aparece en su ventana de correo electrónico. Ninguna solicitud ha salido de su máquina. La transcripción no se sincroniza con ninguna base de datos de proveedores. Todo el flujo tarda unos 30 segundos.
Cuando cada peldaño importa
Los tres peldaños son independientes. Diferentes lectores se preocupan por diferentes. Adapta el peldaño a la restricción.
Si manejas datos regulados (legales, sanitarios, asesoramiento financiero, contratistas gubernamentales), los tres peldaños importan. La mayoría de los marcos de cumplimiento tratan "los datos no salen de la máquina del usuario" como la base más limpia. Apila los tres.
Si eres un desarrollador consciente de la seguridad o trabajas en una empresa con estrictas reglas de egreso de datos, el Peldaño 2 (BYOK) suele ser el más importante. Tu equipo de TI a menudo ya tiene proveedores aprobados y DPA firmados. El enrutamiento a través de tus propias claves mantiene el rastro de auditoría limpio.
Si eres un profesional consciente de la privacidad pero no estás en una industria regulada, el Peldaño 3 (desactivar la sincronización en la nube) es la victoria individual más fácil. Dejas de acumular un historial de transcripciones en la base de datos de un proveedor. El proveedor no puede perder lo que no tiene.
Cómo Contextli es diferente de una herramienta de transcripción
Incluso con los tres peldaños de privacidad apilados, Contextli no es solo una herramienta de transcripción. El objetivo de dictar es obtener texto utilizable, no transcripciones en bruto.
Esta es la brecha que dejan abierta MacWhisper y Superwhisper. Ambos realizan la transcripción localmente, lo cual es excelente para la privacidad. Pero transcriben. No escriben. Si dictas "hola jane tengo ese informe listo lo enviaré pronto", MacWhisper te da esa cadena exacta. Todavía tienes que añadir un saludo, capitalizar, puntuar, estructurar y firmar.
Contextli añade la capa de escritura consciente del contexto sobre la transcripción. La misma dictado, con el Modo Correo electrónico activo, sale como un correo electrónico profesional correctamente dirigido. Cada Modo (Correo electrónico, Mensajería, Notas, LinkedIn, Texto de marketing, Dictado general) se puede personalizar con ejemplos de tu propia escritura para que la salida coincida con tu voz. Nada de esto requiere renunciar a la privacidad. Los ejemplos de personalización también viven localmente.
Lo que no prometemos
Tres advertencias honestas para que el resto sea creíble.
Wispr Flow es más rápido que el modelo local Contextli para la transcripción de pura velocidad. Si no le importa a dónde va su audio y desea el dictado más rápido posible, Wispr Flow gana en esa única dimensión. No competimos en velocidad.
Los modelos locales aún necesitan una máquina moderna. Una MacBook Air de 2013 no ejecutará la transcripción de clase Whisper en tiempo real. Decimos esto claramente porque la tendencia de marketing es ocultarlo.
Contextli no es un producto certificado por HIPAA. La pila local le permite cumplir con los requisitos de cumplimiento de su propia empresa, pero si su flujo de trabajo requiere un Acuerdo de Asociado Comercial o una certificación específica, pregunte primero a su equipo de cumplimiento antes de confiar en cualquier herramienta de dictado, incluida esta.
Preguntas frecuentes
¿Es Contextli una herramienta de dictado privada lista para usar?
Por defecto, Contextli utiliza el procesamiento en la nube para la velocidad, al igual que la mayoría de los competidores. Para hacerlo completamente privado, cambia a modelos locales, opcionalmente activa BYOK y desactiva la sincronización en la nube en la configuración. Los tres niveles son controlados por el usuario, desactivados por defecto para la sincronización en la nube, pero fáciles de habilitar.
¿Contextli alguna vez ve mi audio?
Si habilita los modelos locales, no. El audio se procesa en su máquina y nunca se envía a través de la red. Si permanece en el procesamiento en la nube, el audio va a la tubería de transcripción de Contextli y se elimina después del procesamiento según nuestra política de retención.
¿Cuál es la diferencia entre el Modo de Privacidad de Wispr Flow y la pila de privacidad de Contextli?
El Modo de Privacidad de Wispr Flow es una retención cero del lado del servidor. El audio aún sale de su dispositivo para la transcripción y el reformateo. La opción de modelo local de Contextli significa que el audio nunca sale del dispositivo. Son cosas diferentes, y la diferencia importa más para las industrias reguladas que para el uso profesional general.
¿Puedo usar Contextli sin conexión?
Sí, con los modelos locales habilitados. Tanto la transcripción como la escritura consciente del contexto se ejecutan en su máquina. Internet puede estar apagado. La sincronización en la nube (Nivel 3) es la única característica que requiere Internet, y puede desactivarla.
¿Es BYOK más barato que la suscripción plana de Contextli?
Depende de cuánto dicte. Los usuarios intensivos (más de 2 a 3 horas de dictado por día) a menudo pagan menos por minuto a través de BYOK porque pagan la tarifa por minuto del proveedor directamente. Los usuarios ligeros suelen obtener mejores resultados con la suscripción plana.
¿La Dictado de Apple cuenta como privada?
La Dictado de Apple se ejecuta en el dispositivo en Macs y iPhones recientes, lo que cubre el Nivel 1. Pero Apple aún recopila telemetría de uso, la salida es una transcripción genérica sin personalización y no hay adaptación por canal. Solo por privacidad, la Dictado de Apple está bien. Para el dictado profesional en todos los canales, no es suficiente.
¿Cómo sé que mi modelo local realmente se está ejecutando localmente?
Apague el Wi-Fi e intente dictar. Si la transcripción aún funciona, el modelo se está ejecutando en su máquina. La configuración de Contextli también muestra un indicador de estado para qué motor está activo (local versus nube).
¿Qué sucede con mis notas si desactivo la sincronización en la nube?
Permanecen como archivos locales en una carpeta que usted controla. Puede encontrar la carpeta en la configuración de Contextli (muestra la ruta exacta). Haga una copia de seguridad como cualquier otra carpeta. Elimínelas cuando ya no las necesite.
Dónde ir a continuación
Si la privacidad es su principal preocupación, lea la guía de voz a texto sensible al contexto de Contextli para obtener una descripción general completa de las funciones, y la comparación entre Deepgram y Contextli para ver cómo nos diferenciamos de las herramientas de transcripción de estilo API. Para una perspectiva orientada al cliente sobre el dictado sensible al contexto, consulte Voz a texto de Contextli.
Pruebe Contextli con los tres niveles de privacidad
El nivel gratuito de Contextli incluye 100 créditos por mes sin necesidad de tarjeta de crédito, y la pila de privacidad (modelos locales, BYOK, deshabilitar la sincronización en la nube) está disponible en todos los planes. Configúrelo en cinco minutos y vea cómo su voz permanece en su máquina. Lea más en la página de funciones o consulte las Preguntas frecuentes para obtener detalles sobre el manejo de datos.



